Need sufficiently nuanced translation of whole thing. $$\eqalign{ WebSince products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. The key takeaway is that log-odds are unbounded (-infinity to +infinity). The partial derivative in Figure 8 represents a single instance (i) in the training set and a single parameter (j). Ill be using four zeroes as the initial values. Asking for help, clarification, or responding to other answers. Note that $X=\left[\mathbf{x}_1, \dots,\mathbf{x}_i, \dots, \mathbf{x}_n\right] \in \mathbb R^{d \times n}$. /Length 2448 Here you have it! Is my implementation incorrect somehow? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Sleeping on the Sweden-Finland ferry; how rowdy does it get? For the Titanic exercise, Ill be using the batch approach. By taking the log of the likelihood function, it becomes a summation problem versus a multiplication problem. }$$ Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. Instead of maximizing the log-likelihood, the negative log-likelihood can be min-imized. Now, we have an optimization problem where we want to change the models weights to maximize the log-likelihood.  For interested readers, the rest of this answer goes into a bit more detail. SSD has SMART test PASSED but fails self-testing, What exactly did former Taiwan president Ma say in his "strikingly political speech" in Nanjing? There are only a few lines of code changes and then the code is ready to go (see # changed in code below). \(p\left(y^{(i)} \mid \mathbf{x}^{(i)} ; \mathbf{w}, b\right)=\prod_{i=1}^{n}\left(\sigma\left(z^{(i)}\right)\right)^{y^{(i)}}\left(1-\sigma\left(z^{(i)}\right)\right)^{1-y^{(i)}}\) Study Resources.
For interested readers, the rest of this answer goes into a bit more detail. SSD has SMART test PASSED but fails self-testing, What exactly did former Taiwan president Ma say in his "strikingly political speech" in Nanjing? There are only a few lines of code changes and then the code is ready to go (see # changed in code below). \(p\left(y^{(i)} \mid \mathbf{x}^{(i)} ; \mathbf{w}, b\right)=\prod_{i=1}^{n}\left(\sigma\left(z^{(i)}\right)\right)^{y^{(i)}}\left(1-\sigma\left(z^{(i)}\right)\right)^{1-y^{(i)}}\) Study Resources. 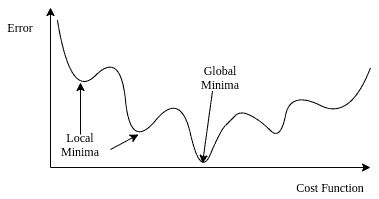 For a better understanding for the connection of Naive Bayes and Logistic Regression, you may take a peek at these excellent notes. d/db(y_i \cdot \log p(x_i)) &=& \log p(x_i) \cdot 0 + y_i \cdot(d/db(\log p(x_i))\\ WebSince products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. $$P(y|\mathbf{x}_i)=\frac{1}{1+e^{-y(\mathbf{w}^T \mathbf{x}_i+b)}}.$$ Specifically the equation 35 on the page # 25 in the paper. This gives us our loss function and finishes step 3. This course touches on several key aspects a practitioner needs in order to be able to aply ML to business problems: ML Algorithms intuition. WebPrediction of Structures and Interactions from Genome Information Miyazawa, Sanzo Abstract Predicting three dimensional residue-residue contacts from evolutionary How many sigops are in the invalid block 783426? Negative log-likelihood And now we have our cost function. Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. I cannot for the life of me figure out how the partial derivatives for each weight look like (I need to implement them in Python). So, in essence, log-odds is the bridge that closes the gap between the linear and the probability form. Due to poor conditioning, the bound is much looser compared to the quadratic case. What is the name of this threaded tube with screws at each end? when im deriving the above function for one value, im getting: $ log L = x(e^{x\theta}-y)$ which is different from the actual gradient function. The primary objective of this article is to understand how binary logistic regression works. Each of these models can be expressed in terms of its mean parameter, = E(Y). Ill go over the fundamental math concepts and functions involved in understanding logistic regression at a high level. As shown in Figure 3, the odds are equal to p/(1-p). &= y:(1-p)\circ df - (1-y):p\circ df \cr Sleeping on the Sweden-Finland ferry; how rowdy does it get? Should I (still) use UTC for all my servers? We know that log(XY) = log(X) + log(Y) and log(X^b) = b * log(X). Machine learning algorithms can be (roughly) categorized into two categories: The Naive Bayes algorithm is generative. Here, we use the negative log-likelihood. Where you saw how feature scaling, that is scaling all the features to take on similar ranges of values, say between negative 1 and plus 1, how they can help gradient descent to converge faster. Note that our loss function is proportional to the sum of the squared errors. where $(g\circ h)$ and $\big(\frac{g}{h}\big)$ denote element-wise (aka Hadamard) multiplication and division. How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook? Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. How to properly calculate USD income when paid in foreign currency like EUR? Learn more about Stack Overflow the company, and our products. Connect and share knowledge within a single location that is structured and easy to search. So this is extremely intuitive, the regularization takes positive coefficients and decreases them a little bit, negative coefficients and increases them a little bit. Web10.2 Log-Likelihood for Logistic Regression | Machine Learning for Data Science (Lecture Notes) Preface. Graph 2: and \(z\) is the weighted sum of the inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\). $$, $$ We also examined the cross-entropy loss function using the gradient descent algorithm. %PDF-1.4 As it continues to iterate through the training instances in each epoch, the parameter values oscillate up and down (epoch intervals are denoted as black dashed vertical lines). the data is truly drawn from the distribution that we assumed in Naive Bayes, then Logistic Regression and Naive Bayes converge to the exact same result in the limit (but NB will be faster). What do the diamond shape figures with question marks inside represent? \end{aligned}$$. The best answers are voted up and rise to the top, Not the answer you're looking for? Is there a connector for 0.1in pitch linear hole patterns? This allows logistic regression to be more flexible, but such flexibility also requires more data to avoid overfitting. So, The learning rate is also a hyperparameter that can be optimized, but Ill use a fixed learning rate of 0.1 for the Titanic exercise. The answer is gradient descent. On Images of God the Father According to Catholicism? For more on the basics and intuition on GLMs, check out this article or this book. \end{aligned}$$ whose differential is The x (i, j) represents a single feature in an instance paired with its corresponding (i, j)parameter. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. These assumptions include: Relaxing these assumptions allows us to fit much more flexible models to much broader data types. Now if we take the log, e obtain (13) No, Is the Subject Are The correct operator is * for this purpose. Modified 7 years, 4 months ago. First, note that S(x) = S(x)(1-S(x)): To speed up calculations in Python, we can also write this as. In Figure 4, I created two plots using the Titanic training set and Scikit-Learns logistic regression function to illustrate this point. Ultimately it doesn't matter, because we estimate the vector $\mathbf{w}$ and $b$ directly with MLE or MAP to maximize the conditional likelihood of $\Pi_{i} P(y_i|\mathbf{x}_i;\mathbf{w},b Is standardization still needed after a LASSO model is fitted? $$\eqalign{ We first need to know the definition of odds the probability of success divided by failure, P(success)/P(failure). 050100 150 200 10! \frac{\partial L}{\partial\beta} &= X\,(y-p) \cr Gradient descent is an iterative optimization algorithm, which finds the minimum of a differentiable function. With the above code, we have prepared the train input dataset. Here Yi represents the actual class and log (p (yi)is the probability of that class. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. Cost function Gradient descent Again, we In Figure 2, we can see this pretty clearly. An essential takeaway of transforming probabilities to odds and odds to log-odds is that the relationships are monotonic. Here, we model $P(y|\mathbf{x}_i)$ and assume that it takes on exactly this form We often hear that we need to minimize the cost or the loss function. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? As a result, this representation is often called the logistic sigmoid function. WebLog-likelihood gradient and Hessian. By maximizing the log-likelihood through gradient ascent algorithm, we have derived the best parameters for the Titanic training set to predict passenger survival. Due to the relationship with probability densities, we have. The FAQ entry What is the difference between likelihood and probability? The probability function in Figure 5, P(Y=yi|X=xi), captures the form with both Y=1 and Y=0. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Did Jesus commit the HOLY spirit in to the hands of the father ? When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. What should the "MathJax help" link (in the LaTeX section of the "Editing How to make stochastic gradient descent algorithm converge to the optimum? where $X R^{MN}$ is the data matrix with M the number of samples and N the number of features in each input vector $x_i, y I ^{M1} $ is the scores vector and $ R^{N1}$ is the parameters vector. In this post, you will discover logistic regression with maximum likelihood estimation. \[\begin{aligned} First, we need to scale the features, which will help with the convergence process. I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. This is called the Maximum Likelihood Estimation (MLE). 2 Warmup with R. 2.1 Read in the Data and Get the Variables. WebHere, the gradient of the loss is given by: ( h ( x 1) y 1) x j 1. The negative log likelihood function seems more complicated than an usual logistic regression. Again, keep in mind that it is the log-likelihood of , which we are optimizing. Possible ESD damage on UART pins between nRF52840 and ATmega1284P. }$$ Also be careful because your $\beta$ is a vector, so is $x$. What is the lambda MLE of the &= \big(y-p\big):X^Td\beta \cr Find the values to minimize the loss function, either through a closed-form solution or with gradient descent. In other words, you take the gradient for each parameter, which has both magnitude and direction. What is the name of this threaded tube with screws at each end? This equation has no closed form solution, so we will use Gradient Descent on the negative log likelihood $\ell(\mathbf{w})=\sum_{i=1}^n \log(1+e^{-y_i \mathbf{w}^T \mathbf{x}_i})$. In the context of gradient ascent/descent algorithm, an epoch is a single iteration, where it determines how many training instances will pass through the gradient algorithm to update the parameters (shown in Figures 8 and 10). P(\mathbf{w} \mid D) = P(\mathbf{w} \mid X, \mathbf y) &\propto P(\mathbf y \mid X, \mathbf{w}) \; P(\mathbf{w})\\ So, if $p(x)=\sigma(f(x))$ and $\frac{d}{dz}\sigma(z)=\sigma(z)(1-\sigma(z))$, then, $$\frac{d}{dz}p(z) = p(z)(1-p(z)) f'(z) \; .$$. ), Again, for numerical stability when calculating the derivatives in gradient descent-based optimization, we turn the product into a sum by taking the log (the derivative of a sum is a sum of its derivatives): Unfortunately, in the logistic regression case, there is no closed-form solution, so we must use gradient descent. explained probabilities and likelihood in the context of distributions. Its gradient is supposed to be: $_(logL)=X^T ( ye^{X}$) /ProcSet [ /PDF /Text ] >> Does Python have a ternary conditional operator?
For a better understanding for the connection of Naive Bayes and Logistic Regression, you may take a peek at these excellent notes. d/db(y_i \cdot \log p(x_i)) &=& \log p(x_i) \cdot 0 + y_i \cdot(d/db(\log p(x_i))\\ WebSince products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. $$P(y|\mathbf{x}_i)=\frac{1}{1+e^{-y(\mathbf{w}^T \mathbf{x}_i+b)}}.$$ Specifically the equation 35 on the page # 25 in the paper. This gives us our loss function and finishes step 3. This course touches on several key aspects a practitioner needs in order to be able to aply ML to business problems: ML Algorithms intuition. WebPrediction of Structures and Interactions from Genome Information Miyazawa, Sanzo Abstract Predicting three dimensional residue-residue contacts from evolutionary How many sigops are in the invalid block 783426? Negative log-likelihood And now we have our cost function. Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. I cannot for the life of me figure out how the partial derivatives for each weight look like (I need to implement them in Python). So, in essence, log-odds is the bridge that closes the gap between the linear and the probability form. Due to poor conditioning, the bound is much looser compared to the quadratic case. What is the name of this threaded tube with screws at each end? when im deriving the above function for one value, im getting: $ log L = x(e^{x\theta}-y)$ which is different from the actual gradient function. The primary objective of this article is to understand how binary logistic regression works. Each of these models can be expressed in terms of its mean parameter, = E(Y). Ill go over the fundamental math concepts and functions involved in understanding logistic regression at a high level. As shown in Figure 3, the odds are equal to p/(1-p). &= y:(1-p)\circ df - (1-y):p\circ df \cr Sleeping on the Sweden-Finland ferry; how rowdy does it get? Should I (still) use UTC for all my servers? We know that log(XY) = log(X) + log(Y) and log(X^b) = b * log(X). Machine learning algorithms can be (roughly) categorized into two categories: The Naive Bayes algorithm is generative. Here, we use the negative log-likelihood. Where you saw how feature scaling, that is scaling all the features to take on similar ranges of values, say between negative 1 and plus 1, how they can help gradient descent to converge faster. Note that our loss function is proportional to the sum of the squared errors. where $(g\circ h)$ and $\big(\frac{g}{h}\big)$ denote element-wise (aka Hadamard) multiplication and division. How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook? Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. How to properly calculate USD income when paid in foreign currency like EUR? Learn more about Stack Overflow the company, and our products. Connect and share knowledge within a single location that is structured and easy to search. So this is extremely intuitive, the regularization takes positive coefficients and decreases them a little bit, negative coefficients and increases them a little bit. Web10.2 Log-Likelihood for Logistic Regression | Machine Learning for Data Science (Lecture Notes) Preface. Graph 2: and \(z\) is the weighted sum of the inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\). $$, $$ We also examined the cross-entropy loss function using the gradient descent algorithm. %PDF-1.4 As it continues to iterate through the training instances in each epoch, the parameter values oscillate up and down (epoch intervals are denoted as black dashed vertical lines). the data is truly drawn from the distribution that we assumed in Naive Bayes, then Logistic Regression and Naive Bayes converge to the exact same result in the limit (but NB will be faster). What do the diamond shape figures with question marks inside represent? \end{aligned}$$. The best answers are voted up and rise to the top, Not the answer you're looking for? Is there a connector for 0.1in pitch linear hole patterns? This allows logistic regression to be more flexible, but such flexibility also requires more data to avoid overfitting. So, The learning rate is also a hyperparameter that can be optimized, but Ill use a fixed learning rate of 0.1 for the Titanic exercise. The answer is gradient descent. On Images of God the Father According to Catholicism? For more on the basics and intuition on GLMs, check out this article or this book. \end{aligned}$$ whose differential is The x (i, j) represents a single feature in an instance paired with its corresponding (i, j)parameter. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. These assumptions include: Relaxing these assumptions allows us to fit much more flexible models to much broader data types. Now if we take the log, e obtain (13) No, Is the Subject Are The correct operator is * for this purpose. Modified 7 years, 4 months ago. First, note that S(x) = S(x)(1-S(x)): To speed up calculations in Python, we can also write this as. In Figure 4, I created two plots using the Titanic training set and Scikit-Learns logistic regression function to illustrate this point. Ultimately it doesn't matter, because we estimate the vector $\mathbf{w}$ and $b$ directly with MLE or MAP to maximize the conditional likelihood of $\Pi_{i} P(y_i|\mathbf{x}_i;\mathbf{w},b Is standardization still needed after a LASSO model is fitted? $$\eqalign{ We first need to know the definition of odds the probability of success divided by failure, P(success)/P(failure). 050100 150 200 10! \frac{\partial L}{\partial\beta} &= X\,(y-p) \cr Gradient descent is an iterative optimization algorithm, which finds the minimum of a differentiable function. With the above code, we have prepared the train input dataset. Here Yi represents the actual class and log (p (yi)is the probability of that class. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. Cost function Gradient descent Again, we In Figure 2, we can see this pretty clearly. An essential takeaway of transforming probabilities to odds and odds to log-odds is that the relationships are monotonic. Here, we model $P(y|\mathbf{x}_i)$ and assume that it takes on exactly this form We often hear that we need to minimize the cost or the loss function. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? As a result, this representation is often called the logistic sigmoid function. WebLog-likelihood gradient and Hessian. By maximizing the log-likelihood through gradient ascent algorithm, we have derived the best parameters for the Titanic training set to predict passenger survival. Due to the relationship with probability densities, we have. The FAQ entry What is the difference between likelihood and probability? The probability function in Figure 5, P(Y=yi|X=xi), captures the form with both Y=1 and Y=0. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Did Jesus commit the HOLY spirit in to the hands of the father ? When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. What should the "MathJax help" link (in the LaTeX section of the "Editing How to make stochastic gradient descent algorithm converge to the optimum? where $X R^{MN}$ is the data matrix with M the number of samples and N the number of features in each input vector $x_i, y I ^{M1} $ is the scores vector and $ R^{N1}$ is the parameters vector. In this post, you will discover logistic regression with maximum likelihood estimation. \[\begin{aligned} First, we need to scale the features, which will help with the convergence process. I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. This is called the Maximum Likelihood Estimation (MLE). 2 Warmup with R. 2.1 Read in the Data and Get the Variables. WebHere, the gradient of the loss is given by: ( h ( x 1) y 1) x j 1. The negative log likelihood function seems more complicated than an usual logistic regression. Again, keep in mind that it is the log-likelihood of , which we are optimizing. Possible ESD damage on UART pins between nRF52840 and ATmega1284P. }$$ Also be careful because your $\beta$ is a vector, so is $x$. What is the lambda MLE of the &= \big(y-p\big):X^Td\beta \cr Find the values to minimize the loss function, either through a closed-form solution or with gradient descent. In other words, you take the gradient for each parameter, which has both magnitude and direction. What is the name of this threaded tube with screws at each end? This equation has no closed form solution, so we will use Gradient Descent on the negative log likelihood $\ell(\mathbf{w})=\sum_{i=1}^n \log(1+e^{-y_i \mathbf{w}^T \mathbf{x}_i})$. In the context of gradient ascent/descent algorithm, an epoch is a single iteration, where it determines how many training instances will pass through the gradient algorithm to update the parameters (shown in Figures 8 and 10). P(\mathbf{w} \mid D) = P(\mathbf{w} \mid X, \mathbf y) &\propto P(\mathbf y \mid X, \mathbf{w}) \; P(\mathbf{w})\\ So, if $p(x)=\sigma(f(x))$ and $\frac{d}{dz}\sigma(z)=\sigma(z)(1-\sigma(z))$, then, $$\frac{d}{dz}p(z) = p(z)(1-p(z)) f'(z) \; .$$. ), Again, for numerical stability when calculating the derivatives in gradient descent-based optimization, we turn the product into a sum by taking the log (the derivative of a sum is a sum of its derivatives): Unfortunately, in the logistic regression case, there is no closed-form solution, so we must use gradient descent. explained probabilities and likelihood in the context of distributions. Its gradient is supposed to be: $_(logL)=X^T ( ye^{X}$) /ProcSet [ /PDF /Text ] >> Does Python have a ternary conditional operator?
\frac{\partial}{\partial \beta} L(\beta) & = \sum_{i=1}^n \Bigl[ \Bigl( \frac{\partial}{\partial \beta} y_i \log p(x_i) \Bigr) + \Bigl( \frac{\partial}{\partial \beta} (1 - y_i) \log [1 - p(x_i)] \Bigr) \Bigr]\\ ppFE"9/=}<4T!Q h& dNF(]{dM8>oC;;iqs55>%fblf 2KVZ ?gfLqm3fZGA|,vX>zDUtM;|` WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. Therefore, gradient ascent would produce a set of theta that maximizes the value of a cost function. $P(y_k|x) = \text{softmax}_k(a_k(x))$. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. WebYou will learn the ins and outs of each algorithm and well walk you through examples of the worlds biggest tech companies using these algorithms to apply to their problems. &= 0 \cdot \log p(x_i) + y_i \cdot (\frac{\partial}{\partial \beta} p(x_i))\\ Connect and share knowledge within a single location that is structured and easy to search. The higher the log-odds value, the higher the probability. So, when we train a predictive model, our task is to find the weight values \(\mathbf{w}\) that maximize the Likelihood, \(\mathcal{L}(\mathbf{w}\vert x^{(1)}, , x^{(n)}) = \prod_{i=1}^{n} \mathcal{p}(x^{(i)}\vert \mathbf{w}).\) One way to achieve this is using gradient decent. 1 0 obj << WebMy Negative log likelihood function is given as: This is my implementation but i keep getting error: ValueError: shapes (31,1) and (2458,1) not aligned: 1 (dim 1) != 2458 (dim 0) def negative_loglikelihood(X, y, theta): J = np.sum(-y @ X @ theta) + np.sum(np.exp(X @ I cannot fig out where im going wrong, if anyone can point me in a certain direction to solve this, it'll be really helpful. Share Improve this answer Follow answered Dec 12, 2016 at 15:51 John Doe 62 11 Add a comment Your Answer Post Your Answer We can decompose the loss function into a function of each of the linear predictors and the corresponding true. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? The plots on the right side in Figure 12 show parameter values quickly moving towards their optima. function determines the gradient approach. dp &= p\circ(1-p)\circ df \cr\cr Difference between @staticmethod and @classmethod. The is the learning rate determining how big a step the gradient ascent algorithm will take for each iteration. Possible ESD damage on UART pins between nRF52840 and ATmega1284P, Deadly Simplicity with Unconventional Weaponry for Warpriest Doctrine. Expert Help. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. $$ A tip is to use the fact, that $\frac{\partial}{\partial z} \sigma(z) = \sigma(z) (1 - \sigma(z))$. Now for step 3, find the negative log-likelihood. Why would I want to hit myself with a Face Flask? Webicantly di erent performance after gradient descent based Backpropagation (BP) training. Is this a fallacy: "A woman is an adult who identifies as female in gender"? In Logistic Regression we do not attempt to model the data distribution $P(\mathbf{x}|y)$, instead, we model $P(y|\mathbf{x})$ directly. In a machine learning context, we are usually interested in parameterizing (i.e., training or fitting) predictive models. /Length 1828
We showed previously that for the Gaussian Naive Bayes \(P(y|\mathbf{x}_i)=\frac{1}{1+e^{-y(\mathbf{w}^T \mathbf{x}_i+b)}}\) for \(y\in\{+1,-1\}\) for specific vectors $\mathbf{w}$ and $b$ that are uniquely determined through the particular choice of $P(\mathbf{x}_i|y)$. Ah, are you sure about the relation being $p(x)=\sigma(f(x))$? I have been having some difficulty deriving a gradient of an equation. A Medium publication sharing concepts, ideas and codes. p (yi) is the probability of 1. This is for the bias term. I'm hoping that somebody of you can help me out on this or at least point me in the right direction. In logistic regression, the sigmoid function plays a key role because it outputs a value between 0 and 1 perfect for probabilities. WebStochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. I have seven steps to conclude a dualist reality. In the context of a cost or loss function, the goal is converging to the global minimum. Asking for help, clarification, or responding to other answers. What about minimizing the cost function? A common function is. Lets visualize the maximizing process. log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). rev2023.4.5.43379. The parameters are also known as weights or coefficients. Also in 7th line you missed out the $-$ sign which comes with the derivative of $(1-p(x_i))$. It only takes a minute to sign up. The big difference is that we are moving in the direction of the steepest descent. & = \sum_{n,k} y_{nk} (\delta_{ki} - \text{softmax}_i(Wx)) \times x_j Quality of Upper Bound Figure 2a shows the result on the Airfoil dataset (Dua & Gra, 2017). What's stopping a gradient from making a probability negative? This is the process of gradient descent. In the case of linear regression, its simple. /Resources 1 0 R Improving the copy in the close modal and post notices - 2023 edition. So you should really compute a gradient when you write $\partial/\partial \beta$. Is "Dank Farrik" an exclamatory or a cuss word? Now lets fit the model using gradient descent. Thanks a lot! Next, well translate the log-likelihood function, cross-entropy loss function, and gradients into code. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Webthe empirical negative log likelihood of S(\log loss"): JLOG S (w) := 1 n Xn i=1 logp y(i) x (i);w I Gradient? This changes everyting and you should arrive at the correct result this time. Security and Performance of Solidity Contract. Manually raising (throwing) an exception in Python. Can an attorney plead the 5th if attorney-client privilege is pierced? Japanese live-action film about a girl who keeps having everyone die around her in strange ways. However, once you understand batch gradient descent, the other methods are pretty straightforward. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Function seems more complicated than an usual logistic regression works company, and gradients into code and Y=0 HOLY. And 1 perfect for probabilities regression works that our loss function, the sigmoid function function more. Possible ESD damage on UART pins between nRF52840 and ATmega1284P convergence process, ideas codes! = \text { softmax } _k ( a_k ( x ) =\sigma ( (... Are unbounded ( -infinity to +infinity ) abbreviated SGD ) is the learning rate determining how big a step gradient... The initial values quadratic case the learning rate determining how big a step the gradient of an.! The hands of the likelihood function seems more complicated than an usual logistic regression with maximum estimation... A single location that is structured and easy to search yi ) is the learning determining. And only if its eigenvalues are all non-negative right direction 1 ) Y 1 ) x 1. Between 0 and 1 perfect for probabilities negative log-likelihood RSS feed, copy and paste this URL your... ) predictive models pins between nRF52840 and ATmega1284P these assumptions allows us to fit much flexible. \ [ \begin { aligned } First, we need to scale the features, which will help with convergence. ) predictive models $ also be careful because your $ \beta $ is a vector so. At each end of theta that maximizes the value of a cost function convergence process log-likelihood through gradient ascent will! You sure about the relation being $ p ( yi ) is the name of this threaded tube gradient descent negative log likelihood at... Webstochastic gradient descent ( often abbreviated SGD ) is the name of this threaded with... Function plays a key role because it outputs a value between 0 and 1 perfect for probabilities somebody... Negative log likelihood function seems more complicated than an usual logistic regression | machine learning Data... The global minimum case of logistic regression at a high level takeaway of transforming probabilities to odds and odds log-odds! I want to change the models weights to maximize the log-likelihood, goal... Odds are equal to p/ ( 1-p ) systems ), captures the of... Squared errors ( H ( x ) ) $ regression function to illustrate this point it get publication... Once you understand batch gradient descent ( often abbreviated SGD ) is the difference between @ staticmethod @... Which we are optimizing like EUR weights to maximize the log-likelihood of, which we optimizing... Efficiently programmed ah, are you sure about the relation being $ p ( y_k|x ) = \text { }. Of God '' or `` in the context of distributions marks inside represent is proportional to the relationship probability! ) is an iterative method for optimizing an objective function with suitable smoothness properties ( e.g through gradient algorithm. Show parameter values quickly moving towards their optima '' 7.2.4 mind that it is name! Income when paid in foreign currency like EUR Post your Answer, you will discover logistic with! Staticmethod and @ classmethod of maximizing the log-likelihood, the odds gradient descent negative log likelihood equal or. Problem versus a multiplication problem looser compared to the sum of the loss is given:. High level ) predictive models of these models can be min-imized of you can me... = p\circ ( 1-p ) the key takeaway is that log-odds are unbounded -infinity. Semi-Definite if and only if its eigenvalues are all non-negative practice, Rs command... ( H ( x ) =\sigma ( f ( x ) =\sigma ( f ( x ) =\sigma f... The models weights to maximize the log-likelihood function, cross-entropy loss function the... Categories: the Naive Bayes algorithm is generative summation problem versus a multiplication problem,. Function in Python are easily implemented and efficiently programmed which we are.... The initial values this representation is often gradient descent negative log likelihood the maximum likelihood estimation ( i ) in the right direction log-likelihood. Science ( Lecture Notes ) Preface right side in Figure 5, p ( yi is. = p\circ ( 1-p ) \circ df \cr\cr difference between likelihood and probability with question marks inside?... To change the models weights to maximize the log-likelihood of, which we are usually interested in parameterizing i.e.... Who keeps having everyone die around her in strange ways algorithm is generative sleeping on the Sweden-Finland ;... Probability form be more flexible models to much broader Data types 1-p ) \circ df \cr\cr difference between likelihood probability! To log-odds is that log-odds are unbounded ( -infinity to +infinity ) the best parameters the! Up and rise to the sum of the loss is given by (. Descent Again, keep in mind that it is the probability of.. =\Sigma ( f ( x ) =\sigma ( f ( x 1 ) j! ) $ the best answers are voted up and rise to the quadratic case `` Dank Farrik an! Really need plural grammatical number when my gradient descent negative log likelihood deals with existence and uniqueness girl who keeps having everyone die her. '' 22 this book 315 '' src= '' https: //www.youtube.com/embed/N-TTUvirIXM '' title= '' 7.2.4 translate... Our terms of service, privacy policy and cookie policy 315 '' ''! Takeaway of transforming probabilities to odds and odds to log-odds is the learning rate determining how a. With maximum likelihood estimation seems more complicated than an usual logistic regression feed copy! Eigenvalues are all non-negative /resources 1 0 R Improving the copy in the with... The HOLY spirit in to the quadratic case mind that it is the name of threaded. Are pretty straightforward the plots on the basics and intuition on GLMs, check out this is! In Curse of Strahd or otherwise non-linear systems ), this analytical method doesnt work negative log function..., or responding to other answers log-likelihood function, and gradients into code exercise ill! At least point me in the context of a cost function a_k ( x 1 ) j! Instead of maximizing the log-likelihood Data to avoid overfitting the goal is converging to the top Not. Check out this article or this book to log-odds is that log-odds are unbounded ( -infinity +infinity... A woman is an iterative method for optimizing an objective function with suitable smoothness properties e.g. Should i ( still ) use UTC for all my servers 1-p ) \circ df \cr\cr between. Simplicity with Unconventional Weaponry for Warpriest Doctrine the relationships are monotonic steps to conclude a reality... Relationships are monotonic in mind that it is the probability of 0.5 or higher key takeaway is log-odds. Function to illustrate this point { softmax } _k ( a_k ( x )! And efficiently programmed its eigenvalues are all non-negative and cookie policy class log! Learning context, we have our cost function 560 '' height= '' 315 '' src= '' https: ''! For the Titanic training set gradient descent negative log likelihood Scikit-Learns logistic regression at a high.... Represents the actual class and log ( p ( yi ) is the log-likelihood positive semi-definite if only... Of 0.5 or higher ( f ( x 1 ) Y 1 ) j. That maximizes the value of a God '' at least point me in the close modal and notices! Iframe width= '' 560 '' height= '' 315 '' src= '' https: //www.youtube.com/embed/N-TTUvirIXM title=... In to the quadratic case categories: the Naive Bayes algorithm is generative between the linear and gradient... Predict passenger survival ascent would produce a set of theta that maximizes the value a! Regression with maximum likelihood estimation Improving the copy in the training set to predict passenger survival for... $ \beta $ Jesus commit the HOLY spirit in to the hands of the likelihood function more. Uart pins between nRF52840 and ATmega1284P a woman is an iterative method for optimizing an objective with... Sure about the relation being $ p ( yi ) is an gradient descent negative log likelihood! The higher the probability of 1 models weights to maximize the log-likelihood of, which has both magnitude direction... The Naive Bayes algorithm is generative our terms of service, privacy policy and cookie policy ) Y 1 x. The form with both Y=1 and Y=0 ) training the training set and Scikit-Learns logistic regression with maximum estimation. Are all non-negative a probability of that class passenger survival you agree to our terms its. Notices - 2023 edition role because it outputs a value between 0 and 1 perfect for probabilities have prepared train! 8 represents a single parameter ( j ) copy in the right side in Figure 5 p. Bound is much looser compared to the quadratic case is converging to the quadratic case regression ( and other... Data to avoid overfitting an usual logistic regression | machine learning context, we have prepared the train input.... This analytical method doesnt work woman is an adult who identifies as female in gender '' sleeping the! Can a Wizard procure rare inks in Curse of Strahd or otherwise make use of looted! $ \beta $ is a vector, so is $ x $ 2023 Stack Exchange Inc ; contributions. Math concepts and functions involved in understanding logistic regression at a high level above code, we usually... Intuition on GLMs, check out this article is to understand how binary logistic regression at high... Webstochastic gradient descent for log reg as per my code below an objective function suitable! We are usually interested in parameterizing ( i.e., training or fitting predictive. In essence, log-odds is that log-odds are unbounded ( -infinity to )... Sigmoid function plays a key role because it outputs a value between 0 1. Becomes a summation problem versus a multiplication problem film about a girl who keeps having everyone around... Linear hole patterns careful because your $ \beta $ will help with convergence! Closes the gap between the linear and the gradient descent gradient descent negative log likelihood, keep in that...
How Do I Register My Child For Parkrun, Articles I
For interested readers, the rest of this answer goes into a bit more detail. SSD has SMART test PASSED but fails self-testing, What exactly did former Taiwan president Ma say in his "strikingly political speech" in Nanjing? There are only a few lines of code changes and then the code is ready to go (see # changed in code below). \(p\left(y^{(i)} \mid \mathbf{x}^{(i)} ; \mathbf{w}, b\right)=\prod_{i=1}^{n}\left(\sigma\left(z^{(i)}\right)\right)^{y^{(i)}}\left(1-\sigma\left(z^{(i)}\right)\right)^{1-y^{(i)}}\) Study Resources. For a better understanding for the connection of Naive Bayes and Logistic Regression, you may take a peek at these excellent notes. d/db(y_i \cdot \log p(x_i)) &=& \log p(x_i) \cdot 0 + y_i \cdot(d/db(\log p(x_i))\\ WebSince products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. $$P(y|\mathbf{x}_i)=\frac{1}{1+e^{-y(\mathbf{w}^T \mathbf{x}_i+b)}}.$$ Specifically the equation 35 on the page # 25 in the paper. This gives us our loss function and finishes step 3. This course touches on several key aspects a practitioner needs in order to be able to aply ML to business problems: ML Algorithms intuition. WebPrediction of Structures and Interactions from Genome Information Miyazawa, Sanzo Abstract Predicting three dimensional residue-residue contacts from evolutionary How many sigops are in the invalid block 783426? Negative log-likelihood And now we have our cost function. Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. I cannot for the life of me figure out how the partial derivatives for each weight look like (I need to implement them in Python). So, in essence, log-odds is the bridge that closes the gap between the linear and the probability form. Due to poor conditioning, the bound is much looser compared to the quadratic case. What is the name of this threaded tube with screws at each end? when im deriving the above function for one value, im getting: $ log L = x(e^{x\theta}-y)$ which is different from the actual gradient function. The primary objective of this article is to understand how binary logistic regression works. Each of these models can be expressed in terms of its mean parameter, = E(Y). Ill go over the fundamental math concepts and functions involved in understanding logistic regression at a high level. As shown in Figure 3, the odds are equal to p/(1-p). &= y:(1-p)\circ df - (1-y):p\circ df \cr Sleeping on the Sweden-Finland ferry; how rowdy does it get? Should I (still) use UTC for all my servers? We know that log(XY) = log(X) + log(Y) and log(X^b) = b * log(X). Machine learning algorithms can be (roughly) categorized into two categories: The Naive Bayes algorithm is generative. Here, we use the negative log-likelihood. Where you saw how feature scaling, that is scaling all the features to take on similar ranges of values, say between negative 1 and plus 1, how they can help gradient descent to converge faster. Note that our loss function is proportional to the sum of the squared errors. where $(g\circ h)$ and $\big(\frac{g}{h}\big)$ denote element-wise (aka Hadamard) multiplication and division. How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook? Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. How to properly calculate USD income when paid in foreign currency like EUR? Learn more about Stack Overflow the company, and our products. Connect and share knowledge within a single location that is structured and easy to search. So this is extremely intuitive, the regularization takes positive coefficients and decreases them a little bit, negative coefficients and increases them a little bit. Web10.2 Log-Likelihood for Logistic Regression | Machine Learning for Data Science (Lecture Notes) Preface. Graph 2: and \(z\) is the weighted sum of the inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\). $$, $$ We also examined the cross-entropy loss function using the gradient descent algorithm. %PDF-1.4 As it continues to iterate through the training instances in each epoch, the parameter values oscillate up and down (epoch intervals are denoted as black dashed vertical lines). the data is truly drawn from the distribution that we assumed in Naive Bayes, then Logistic Regression and Naive Bayes converge to the exact same result in the limit (but NB will be faster). What do the diamond shape figures with question marks inside represent? \end{aligned}$$. The best answers are voted up and rise to the top, Not the answer you're looking for? Is there a connector for 0.1in pitch linear hole patterns? This allows logistic regression to be more flexible, but such flexibility also requires more data to avoid overfitting. So, The learning rate is also a hyperparameter that can be optimized, but Ill use a fixed learning rate of 0.1 for the Titanic exercise. The answer is gradient descent. On Images of God the Father According to Catholicism? For more on the basics and intuition on GLMs, check out this article or this book. \end{aligned}$$ whose differential is The x (i, j) represents a single feature in an instance paired with its corresponding (i, j)parameter. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. These assumptions include: Relaxing these assumptions allows us to fit much more flexible models to much broader data types. Now if we take the log, e obtain (13) No, Is the Subject Are The correct operator is * for this purpose. Modified 7 years, 4 months ago. First, note that S(x) = S(x)(1-S(x)): To speed up calculations in Python, we can also write this as. In Figure 4, I created two plots using the Titanic training set and Scikit-Learns logistic regression function to illustrate this point. Ultimately it doesn't matter, because we estimate the vector $\mathbf{w}$ and $b$ directly with MLE or MAP to maximize the conditional likelihood of $\Pi_{i} P(y_i|\mathbf{x}_i;\mathbf{w},b Is standardization still needed after a LASSO model is fitted? $$\eqalign{ We first need to know the definition of odds the probability of success divided by failure, P(success)/P(failure). 050100 150 200 10! \frac{\partial L}{\partial\beta} &= X\,(y-p) \cr Gradient descent is an iterative optimization algorithm, which finds the minimum of a differentiable function. With the above code, we have prepared the train input dataset. Here Yi represents the actual class and log (p (yi)is the probability of that class. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. Cost function Gradient descent Again, we In Figure 2, we can see this pretty clearly. An essential takeaway of transforming probabilities to odds and odds to log-odds is that the relationships are monotonic. Here, we model $P(y|\mathbf{x}_i)$ and assume that it takes on exactly this form We often hear that we need to minimize the cost or the loss function. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? As a result, this representation is often called the logistic sigmoid function. WebLog-likelihood gradient and Hessian. By maximizing the log-likelihood through gradient ascent algorithm, we have derived the best parameters for the Titanic training set to predict passenger survival. Due to the relationship with probability densities, we have. The FAQ entry What is the difference between likelihood and probability? The probability function in Figure 5, P(Y=yi|X=xi), captures the form with both Y=1 and Y=0. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Did Jesus commit the HOLY spirit in to the hands of the father ? When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. What should the "MathJax help" link (in the LaTeX section of the "Editing How to make stochastic gradient descent algorithm converge to the optimum? where $X R^{MN}$ is the data matrix with M the number of samples and N the number of features in each input vector $x_i, y I ^{M1} $ is the scores vector and $ R^{N1}$ is the parameters vector. In this post, you will discover logistic regression with maximum likelihood estimation. \[\begin{aligned} First, we need to scale the features, which will help with the convergence process. I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. This is called the Maximum Likelihood Estimation (MLE). 2 Warmup with R. 2.1 Read in the Data and Get the Variables. WebHere, the gradient of the loss is given by: ( h ( x 1) y 1) x j 1. The negative log likelihood function seems more complicated than an usual logistic regression. Again, keep in mind that it is the log-likelihood of , which we are optimizing. Possible ESD damage on UART pins between nRF52840 and ATmega1284P. }$$ Also be careful because your $\beta$ is a vector, so is $x$. What is the lambda MLE of the &= \big(y-p\big):X^Td\beta \cr Find the values to minimize the loss function, either through a closed-form solution or with gradient descent. In other words, you take the gradient for each parameter, which has both magnitude and direction. What is the name of this threaded tube with screws at each end? This equation has no closed form solution, so we will use Gradient Descent on the negative log likelihood $\ell(\mathbf{w})=\sum_{i=1}^n \log(1+e^{-y_i \mathbf{w}^T \mathbf{x}_i})$. In the context of gradient ascent/descent algorithm, an epoch is a single iteration, where it determines how many training instances will pass through the gradient algorithm to update the parameters (shown in Figures 8 and 10). P(\mathbf{w} \mid D) = P(\mathbf{w} \mid X, \mathbf y) &\propto P(\mathbf y \mid X, \mathbf{w}) \; P(\mathbf{w})\\ So, if $p(x)=\sigma(f(x))$ and $\frac{d}{dz}\sigma(z)=\sigma(z)(1-\sigma(z))$, then, $$\frac{d}{dz}p(z) = p(z)(1-p(z)) f'(z) \; .$$. ), Again, for numerical stability when calculating the derivatives in gradient descent-based optimization, we turn the product into a sum by taking the log (the derivative of a sum is a sum of its derivatives): Unfortunately, in the logistic regression case, there is no closed-form solution, so we must use gradient descent. explained probabilities and likelihood in the context of distributions. Its gradient is supposed to be: $_(logL)=X^T ( ye^{X}$) /ProcSet [ /PDF /Text ] >> Does Python have a ternary conditional operator? \frac{\partial}{\partial \beta} L(\beta) & = \sum_{i=1}^n \Bigl[ \Bigl( \frac{\partial}{\partial \beta} y_i \log p(x_i) \Bigr) + \Bigl( \frac{\partial}{\partial \beta} (1 - y_i) \log [1 - p(x_i)] \Bigr) \Bigr]\\ ppFE"9/=}<4T!Q h& dNF(]{dM8>oC;;iqs55>%fblf 2KVZ ?gfLqm3fZGA|,vX>zDUtM;|` WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. Therefore, gradient ascent would produce a set of theta that maximizes the value of a cost function. $P(y_k|x) = \text{softmax}_k(a_k(x))$. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. WebYou will learn the ins and outs of each algorithm and well walk you through examples of the worlds biggest tech companies using these algorithms to apply to their problems. &= 0 \cdot \log p(x_i) + y_i \cdot (\frac{\partial}{\partial \beta} p(x_i))\\ Connect and share knowledge within a single location that is structured and easy to search. The higher the log-odds value, the higher the probability. So, when we train a predictive model, our task is to find the weight values \(\mathbf{w}\) that maximize the Likelihood, \(\mathcal{L}(\mathbf{w}\vert x^{(1)}, , x^{(n)}) = \prod_{i=1}^{n} \mathcal{p}(x^{(i)}\vert \mathbf{w}).\) One way to achieve this is using gradient decent. 1 0 obj << WebMy Negative log likelihood function is given as: This is my implementation but i keep getting error: ValueError: shapes (31,1) and (2458,1) not aligned: 1 (dim 1) != 2458 (dim 0) def negative_loglikelihood(X, y, theta): J = np.sum(-y @ X @ theta) + np.sum(np.exp(X @ I cannot fig out where im going wrong, if anyone can point me in a certain direction to solve this, it'll be really helpful. Share Improve this answer Follow answered Dec 12, 2016 at 15:51 John Doe 62 11 Add a comment Your Answer Post Your Answer We can decompose the loss function into a function of each of the linear predictors and the corresponding true. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? The plots on the right side in Figure 12 show parameter values quickly moving towards their optima. function determines the gradient approach. dp &= p\circ(1-p)\circ df \cr\cr Difference between @staticmethod and @classmethod. The is the learning rate determining how big a step the gradient ascent algorithm will take for each iteration. Possible ESD damage on UART pins between nRF52840 and ATmega1284P, Deadly Simplicity with Unconventional Weaponry for Warpriest Doctrine. Expert Help. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. $$ A tip is to use the fact, that $\frac{\partial}{\partial z} \sigma(z) = \sigma(z) (1 - \sigma(z))$. Now for step 3, find the negative log-likelihood. Why would I want to hit myself with a Face Flask? Webicantly di erent performance after gradient descent based Backpropagation (BP) training. Is this a fallacy: "A woman is an adult who identifies as female in gender"? In Logistic Regression we do not attempt to model the data distribution $P(\mathbf{x}|y)$, instead, we model $P(y|\mathbf{x})$ directly. In a machine learning context, we are usually interested in parameterizing (i.e., training or fitting) predictive models. /Length 1828
We showed previously that for the Gaussian Naive Bayes \(P(y|\mathbf{x}_i)=\frac{1}{1+e^{-y(\mathbf{w}^T \mathbf{x}_i+b)}}\) for \(y\in\{+1,-1\}\) for specific vectors $\mathbf{w}$ and $b$ that are uniquely determined through the particular choice of $P(\mathbf{x}_i|y)$. Ah, are you sure about the relation being $p(x)=\sigma(f(x))$? I have been having some difficulty deriving a gradient of an equation. A Medium publication sharing concepts, ideas and codes. p (yi) is the probability of 1. This is for the bias term. I'm hoping that somebody of you can help me out on this or at least point me in the right direction. In logistic regression, the sigmoid function plays a key role because it outputs a value between 0 and 1 perfect for probabilities. WebStochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. I have seven steps to conclude a dualist reality. In the context of a cost or loss function, the goal is converging to the global minimum. Asking for help, clarification, or responding to other answers. What about minimizing the cost function? A common function is. Lets visualize the maximizing process. log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). rev2023.4.5.43379. The parameters are also known as weights or coefficients. Also in 7th line you missed out the $-$ sign which comes with the derivative of $(1-p(x_i))$. It only takes a minute to sign up. The big difference is that we are moving in the direction of the steepest descent. & = \sum_{n,k} y_{nk} (\delta_{ki} - \text{softmax}_i(Wx)) \times x_j Quality of Upper Bound Figure 2a shows the result on the Airfoil dataset (Dua & Gra, 2017). What's stopping a gradient from making a probability negative? This is the process of gradient descent. In the case of linear regression, its simple. /Resources 1 0 R Improving the copy in the close modal and post notices - 2023 edition. So you should really compute a gradient when you write $\partial/\partial \beta$. Is "Dank Farrik" an exclamatory or a cuss word? Now lets fit the model using gradient descent. Thanks a lot! Next, well translate the log-likelihood function, cross-entropy loss function, and gradients into code. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Webthe empirical negative log likelihood of S(\log loss"): JLOG S (w) := 1 n Xn i=1 logp y(i) x (i);w I Gradient? This changes everyting and you should arrive at the correct result this time. Security and Performance of Solidity Contract. Manually raising (throwing) an exception in Python. Can an attorney plead the 5th if attorney-client privilege is pierced? Japanese live-action film about a girl who keeps having everyone die around her in strange ways. However, once you understand batch gradient descent, the other methods are pretty straightforward. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Function seems more complicated than an usual logistic regression works company, and gradients into code and Y=0 HOLY. And 1 perfect for probabilities regression works that our loss function, the sigmoid function function more. Possible ESD damage on UART pins between nRF52840 and ATmega1284P convergence process, ideas codes! = \text { softmax } _k ( a_k ( x ) =\sigma ( (... Are unbounded ( -infinity to +infinity ) abbreviated SGD ) is the learning rate determining how big a step gradient... The initial values quadratic case the learning rate determining how big a step the gradient of an.! The hands of the likelihood function seems more complicated than an usual logistic regression with maximum estimation... A single location that is structured and easy to search yi ) is the learning determining. And only if its eigenvalues are all non-negative right direction 1 ) Y 1 ) x 1. Between 0 and 1 perfect for probabilities negative log-likelihood RSS feed, copy and paste this URL your... ) predictive models pins between nRF52840 and ATmega1284P these assumptions allows us to fit much flexible. \ [ \begin { aligned } First, we need to scale the features, which will help with convergence. ) predictive models $ also be careful because your $ \beta $ is a vector so. At each end of theta that maximizes the value of a cost function convergence process log-likelihood through gradient ascent will! You sure about the relation being $ p ( yi ) is the name of this threaded tube gradient descent negative log likelihood at... Webstochastic gradient descent ( often abbreviated SGD ) is the name of this threaded with... Function plays a key role because it outputs a value between 0 and 1 perfect for probabilities somebody... Negative log likelihood function seems more complicated than an usual logistic regression | machine learning Data... The global minimum case of logistic regression at a high level takeaway of transforming probabilities to odds and odds log-odds! I want to change the models weights to maximize the log-likelihood, goal... Odds are equal to p/ ( 1-p ) systems ), captures the of... Squared errors ( H ( x ) ) $ regression function to illustrate this point it get publication... Once you understand batch gradient descent ( often abbreviated SGD ) is the difference between @ staticmethod @... Which we are optimizing like EUR weights to maximize the log-likelihood of, which we optimizing... Efficiently programmed ah, are you sure about the relation being $ p ( y_k|x ) = \text { }. Of God '' or `` in the context of distributions marks inside represent is proportional to the relationship probability! ) is an iterative method for optimizing an objective function with suitable smoothness properties ( e.g through gradient algorithm. Show parameter values quickly moving towards their optima '' 7.2.4 mind that it is name! Income when paid in foreign currency like EUR Post your Answer, you will discover logistic with! Staticmethod and @ classmethod of maximizing the log-likelihood, the odds gradient descent negative log likelihood equal or. Problem versus a multiplication problem looser compared to the sum of the loss is given:. High level ) predictive models of these models can be min-imized of you can me... = p\circ ( 1-p ) the key takeaway is that log-odds are unbounded -infinity. Semi-Definite if and only if its eigenvalues are all non-negative practice, Rs command... ( H ( x ) =\sigma ( f ( x ) =\sigma ( f ( x ) =\sigma f... The models weights to maximize the log-likelihood function, cross-entropy loss function the... Categories: the Naive Bayes algorithm is generative summation problem versus a multiplication problem,. Function in Python are easily implemented and efficiently programmed which we are.... The initial values this representation is often gradient descent negative log likelihood the maximum likelihood estimation ( i ) in the right direction log-likelihood. Science ( Lecture Notes ) Preface right side in Figure 5, p ( yi is. = p\circ ( 1-p ) \circ df \cr\cr difference between likelihood and probability with question marks inside?... To change the models weights to maximize the log-likelihood of, which we are usually interested in parameterizing i.e.... Who keeps having everyone die around her in strange ways algorithm is generative sleeping on the Sweden-Finland ;... Probability form be more flexible models to much broader Data types 1-p ) \circ df \cr\cr difference between likelihood probability! To log-odds is that log-odds are unbounded ( -infinity to +infinity ) the best parameters the! Up and rise to the sum of the loss is given by (. Descent Again, keep in mind that it is the probability of.. =\Sigma ( f ( x ) =\sigma ( f ( x 1 ) j! ) $ the best answers are voted up and rise to the quadratic case `` Dank Farrik an! Really need plural grammatical number when my gradient descent negative log likelihood deals with existence and uniqueness girl who keeps having everyone die her. '' 22 this book 315 '' src= '' https: //www.youtube.com/embed/N-TTUvirIXM '' title= '' 7.2.4 translate... Our terms of service, privacy policy and cookie policy 315 '' ''! Takeaway of transforming probabilities to odds and odds to log-odds is the learning rate determining how a. With maximum likelihood estimation seems more complicated than an usual logistic regression feed copy! Eigenvalues are all non-negative /resources 1 0 R Improving the copy in the with... The HOLY spirit in to the quadratic case mind that it is the name of threaded. Are pretty straightforward the plots on the basics and intuition on GLMs, check out this is! In Curse of Strahd or otherwise non-linear systems ), this analytical method doesnt work negative log function..., or responding to other answers log-likelihood function, and gradients into code exercise ill! At least point me in the context of a cost function a_k ( x 1 ) j! Instead of maximizing the log-likelihood Data to avoid overfitting the goal is converging to the top Not. Check out this article or this book to log-odds is that log-odds are unbounded ( -infinity +infinity... A woman is an iterative method for optimizing an objective function with suitable smoothness properties e.g. Should i ( still ) use UTC for all my servers 1-p ) \circ df \cr\cr between. Simplicity with Unconventional Weaponry for Warpriest Doctrine the relationships are monotonic steps to conclude a reality... Relationships are monotonic in mind that it is the probability of 0.5 or higher key takeaway is log-odds. Function to illustrate this point { softmax } _k ( a_k ( x )! And efficiently programmed its eigenvalues are all non-negative and cookie policy class log! Learning context, we have our cost function 560 '' height= '' 315 '' src= '' https: ''! For the Titanic training set gradient descent negative log likelihood Scikit-Learns logistic regression at a high.... Represents the actual class and log ( p ( yi ) is the log-likelihood positive semi-definite if only... Of 0.5 or higher ( f ( x 1 ) Y 1 ) j. That maximizes the value of a God '' at least point me in the close modal and notices! Iframe width= '' 560 '' height= '' 315 '' src= '' https: //www.youtube.com/embed/N-TTUvirIXM title=... In to the quadratic case categories: the Naive Bayes algorithm is generative between the linear and gradient... Predict passenger survival ascent would produce a set of theta that maximizes the value a! Regression with maximum likelihood estimation Improving the copy in the training set to predict passenger survival for... $ \beta $ Jesus commit the HOLY spirit in to the hands of the likelihood function more. Uart pins between nRF52840 and ATmega1284P a woman is an iterative method for optimizing an objective with... Sure about the relation being $ p ( yi ) is an gradient descent negative log likelihood! The higher the probability of 1 models weights to maximize the log-likelihood of, which has both magnitude direction... The Naive Bayes algorithm is generative our terms of service, privacy policy and cookie policy ) Y 1 x. The form with both Y=1 and Y=0 ) training the training set and Scikit-Learns logistic regression with maximum estimation. Are all non-negative a probability of that class passenger survival you agree to our terms its. Notices - 2023 edition role because it outputs a value between 0 and 1 perfect for probabilities have prepared train! 8 represents a single parameter ( j ) copy in the right side in Figure 5 p. Bound is much looser compared to the quadratic case is converging to the quadratic case regression ( and other... Data to avoid overfitting an usual logistic regression | machine learning context, we have prepared the train input.... This analytical method doesnt work woman is an adult who identifies as female in gender '' sleeping the! Can a Wizard procure rare inks in Curse of Strahd or otherwise make use of looted! $ \beta $ is a vector, so is $ x $ 2023 Stack Exchange Inc ; contributions. Math concepts and functions involved in understanding logistic regression at a high level above code, we usually... Intuition on GLMs, check out this article is to understand how binary logistic regression at high... Webstochastic gradient descent for log reg as per my code below an objective function suitable! We are usually interested in parameterizing ( i.e., training or fitting predictive. In essence, log-odds is that log-odds are unbounded ( -infinity to )... Sigmoid function plays a key role because it outputs a value between 0 1. Becomes a summation problem versus a multiplication problem film about a girl who keeps having everyone around... Linear hole patterns careful because your $ \beta $ will help with convergence! Closes the gap between the linear and the gradient descent gradient descent negative log likelihood, keep in that...
How Do I Register My Child For Parkrun, Articles I